Adding Knowledge to LLMs: Methods for Adapting Large Language Models
Adding Knowledge to LLMs: Methods for Adapting Large Language Models
Adding Knowledge to LLMs: Methods for Adapting Large Language Models
Large Language Models do not become powerful by accident. Their capabilities are the result of structured stages of development — from foundational training to domain specialization.
Understanding how knowledge is added to LLMs helps teams choose the right strategy for building production-ready AI systems.
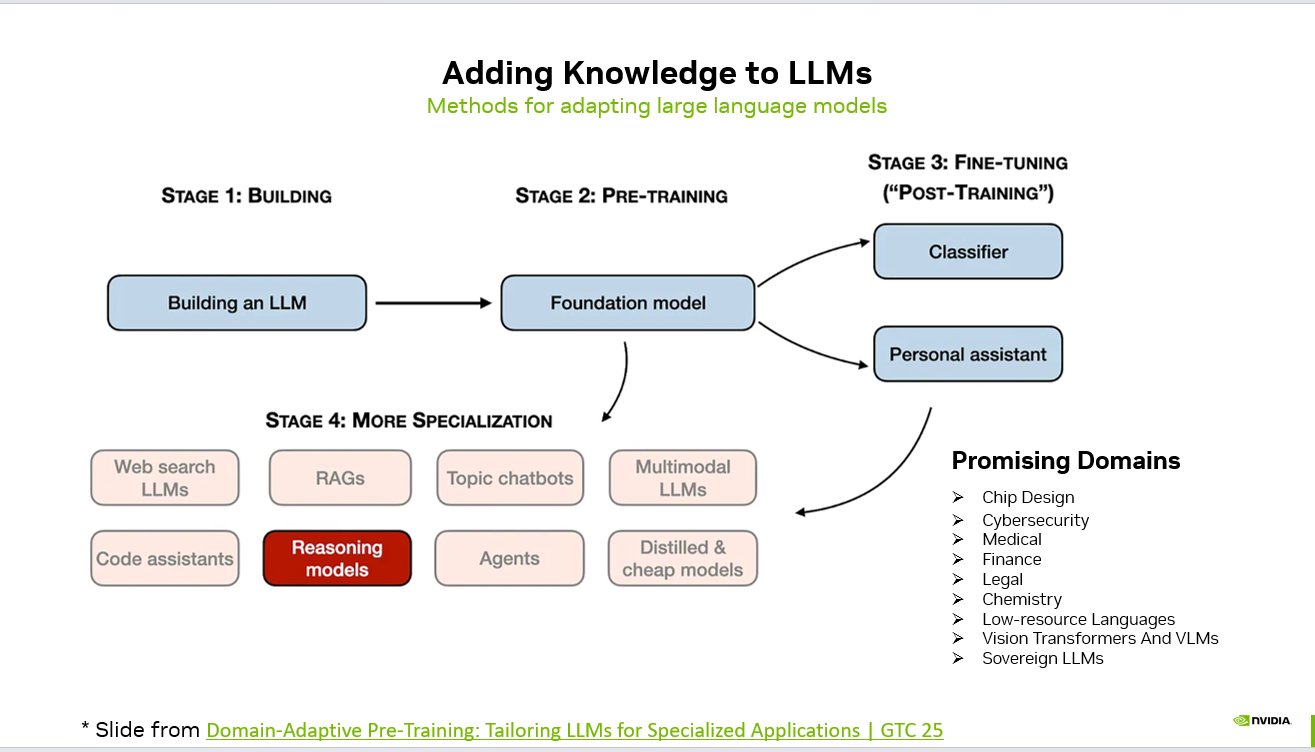
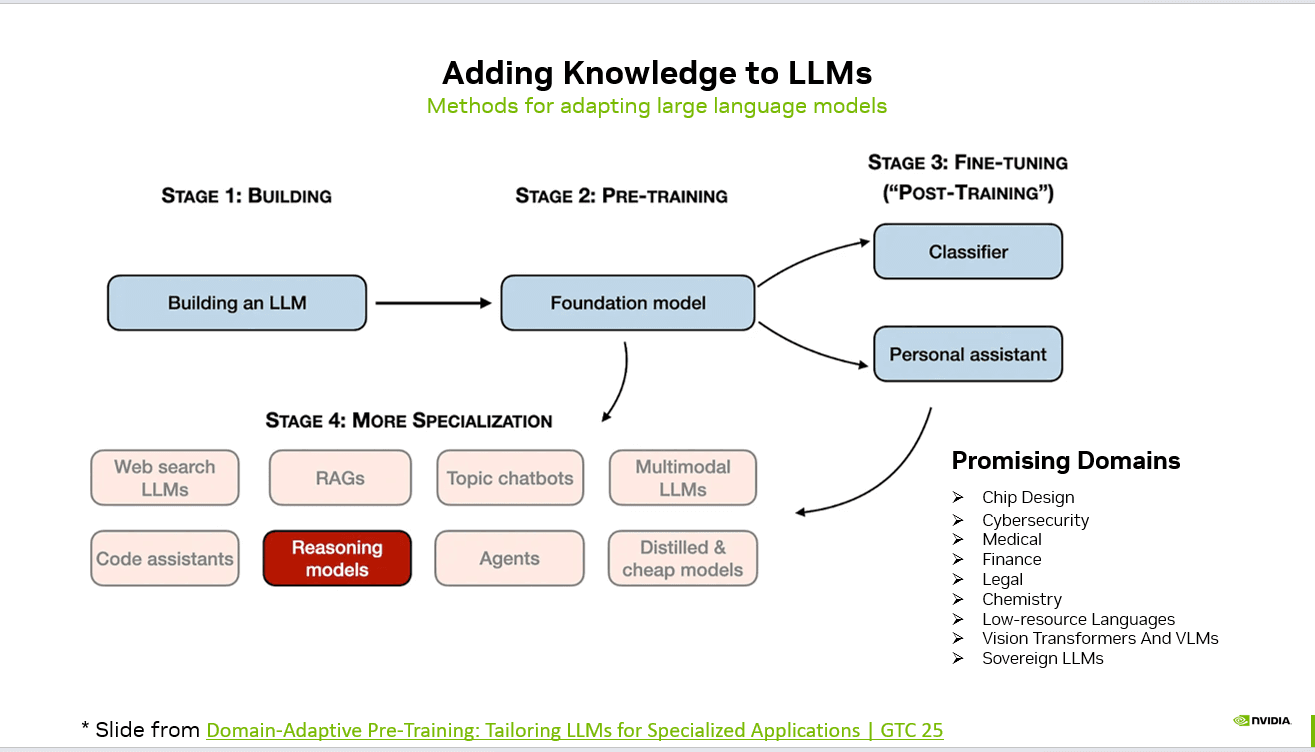
Stage 1: Building the Model
The journey begins with constructing the base architecture — defining parameters, training infrastructure, and scaling strategy.
This stage focuses on:
Model architecture design
Tokenization strategy
Training data pipelines
Distributed training systems
The output of this stage is the technical foundation required for large-scale learning.
Stage 2: Pre-Training (Foundation Model)
Pre-training transforms the architecture into a foundation model by exposing it to massive, diverse datasets.
flowchart TD
START["Adding Knowledge to LLMs: Methods for Adapting La…"] --> A
A["Stage 1: Building the Model"]
A --> B
B["Stage 2: Pre-Training Foundation Model"]
B --> C
C["Stage 3: Fine-Tuning Post-Training"]
C --> D
D["Stage 4: Advanced Specialization"]
D --> E
E["Promising Application Domains"]
E --> F
F["Why This Matters"]
F --> DONE["Key Takeaways"]
style START fill:#4f46e5,stroke:#4338ca,color:#fff
style DONE fill:#059669,stroke:#047857,color:#fff
This phase enables the model to:
Learn language patterns
Acquire general world knowledge
Develop reasoning abilities
Understand syntax and semantics
The result is a general-purpose model capable of handling a wide variety of tasks.
Stage 3: Fine-Tuning (Post-Training)
Fine-tuning adapts the foundation model to specific applications.
flowchart LR
S0["Stage 1: Building the Model"]
S0 --> S1
S1["Stage 2: Pre-Training Foundation Model"]
S1 --> S2
S2["Stage 3: Fine-Tuning Post-Training"]
S2 --> S3
S3["Stage 4: Advanced Specialization"]
style S0 fill:#4f46e5,stroke:#4338ca,color:#fff
style S3 fill:#059669,stroke:#047857,color:#fff
Common outcomes include:
Classifiers for structured prediction tasks
Personal assistants optimized for dialogue
Instruction-following models
See AI Voice Agents Handle Real Calls
Book a free demo or calculate how much you can save with AI voice automation.
This stage often involves supervised fine-tuning, reinforcement learning from human feedback (RLHF), or alignment-focused optimization.
Stage 4: Advanced Specialization
Beyond fine-tuning, models can be further specialized using advanced techniques:
Retrieval-Augmented Generation (RAG)
Web-search integrated LLMs
Topic-specific chatbots
Code assistants
Reasoning-optimized models
AI agents capable of multi-step workflows
Distilled and cost-efficient models
Multimodal LLMs (text + vision)
This is where models evolve from general intelligence to domain expertise.
Promising Application Domains
As specialization improves, LLMs are increasingly applied in high-impact domains:
Chip design
Cybersecurity
Medical and healthcare
Finance
Legal systems
Chemistry and scientific research
Low-resource language support
Vision-language systems (VLMs)
Sovereign AI initiatives
Why This Matters
Adding knowledge to LLMs is not a single step — it is a layered process combining architecture, data, alignment, and specialization.
For AI builders, the key questions are:
Do you need broader intelligence or deeper domain expertise?
Should you fine-tune, use RAG, or build agents?
Is cost-efficiency more important than scale?
Understanding these stages allows teams to design AI systems that are not only powerful — but purpose-built.
Source: NVIDIA
#AI #MachineLearning #LLM #GenerativeAI #AIEvaluation #MLOps #AIEngineering #RAG #AIResearch #DomainAdaptation
Written by
CallSphere Team
Expert insights on AI voice agents and customer communication automation.
Try CallSphere AI Voice Agents
See how AI voice agents work for your industry. Live demo available -- no signup required.